Beyond the Promise: How Federated AI Proves It Keeps Data Private
Designing a system to keep data private is not the same as proving it does.

Lucas Beerens

Salman Toor
June 25, 2026
A hospital wants to get better at spotting disease in medical scans. It has useful data, but so do dozens of other hospitals, and a model trained on all of that data together would be far stronger than one trained on any single hospital's records. The problem is that none of them can move patient data out of the building, let alone pool it in one place. Federated learning offers a way around this. Instead of bringing the data to the model, it brings the model to the data: a shared model is sent out to each hospital, trained locally on scans that never leave the premises, and only the resulting updates are sent back to be merged into the common model. The hospitals build one model together, and not a single patient record changes hands.
It is a clever answer to a hard problem. But it rests on a promise: that sharing the model updates, and never the data itself, is enough to keep patient information private. Before a deployment like this goes live, someone responsible for it will want to know that the promise holds, not just in principle but in practice, under the real conditions the system will run in.
And that is the real question. Not whether the system was designed to keep data private, but whether it can be shown to. When the data belongs to patients, the difference between the two matters a great deal.
The gap between secure design and proven security
Federated learning is a real advance in privacy-preserving AI. Instead of gathering data in one central location, each participating node trains the shared model locally and sends back only mathematical updates. The underlying data stays where it was created.
This is a principled design rather than a workaround, and it has unlocked collaboration on data that could never otherwise be combined: hospitals that cannot share records, companies that compete with one another, any setting where pooling raw data is impractical or simply not allowed.
But designing a system to protect data is not the same as proving that it does, and every field that handles sensitive information seriously treats that distinction as fundamental. In banking, medical devices, and critical infrastructure, a system earns the word "secure" by being tested, not by good intentions alone.
Federated learning is no exception. Even though raw data never leaves a hospital, researchers have found that in some scenarios the model updates it sends back can carry traces of the data with them. It is a well understood phenomenon, and it points somewhere constructive: like any maturing technology that handles sensitive information, federated learning benefits from a routine habit of auditing. In most security fields that habit is long established. In federated learning, it is still being built.
The gap between a lab and a live network
The research community has made real progress here. LeakPro, a research project we are part of, brings together a wide range of these auditing techniques in one place, making it possible to measure how much a single model update can reveal about the data behind it. It is a powerful way to map out where the weak points lie.
The harder problem is putting that capability to work in the real world.
Evaluating a model in a controlled research environment is a very different task from auditing a network running in the field. In the lab, everything is known and can be arranged to suit the experiment: the settings are fixed, the data is available, and the whole thing can run on a single machine. Conditions can even be chosen to make leakage easier to measure, which is what you want when testing whether a new attack is an improvement. A real deployment offers none of this. A hospital network runs its models on a patchwork of hardware, with local settings that differ from one site to the next and are not always known in advance. The data is real and must never leak, and the clinical work the system supports cannot be paused for the sake of a test.
A fixed audit script cannot keep up with any of this. It runs on one machine to check one configuration and reports a result that describes the lab rather than the field. Producing findings that mean something under real conditions takes more than a script. It takes a module built for live deployments that plugs into the federated learning platform.
Adversarial Modelling Module: from security assumptions to security evidence
This is the gap the Adversarial Modelling Module, or AMM, is built to close. It draws on the attacks LeakPro makes available and puts them to work where they count: inside a real, running federated network using Scaleout Edge. Figure 1 shows how AMM plugs into Scaleout Edge, using a group of cooperating hospitals as the example. Because the audit runs inside the same platform as the training, testing a network's privacy stops being a separate exercise carried out after the fact and becomes part of how the network runs. Three qualities make that possible, and each one answers a problem we have already met.
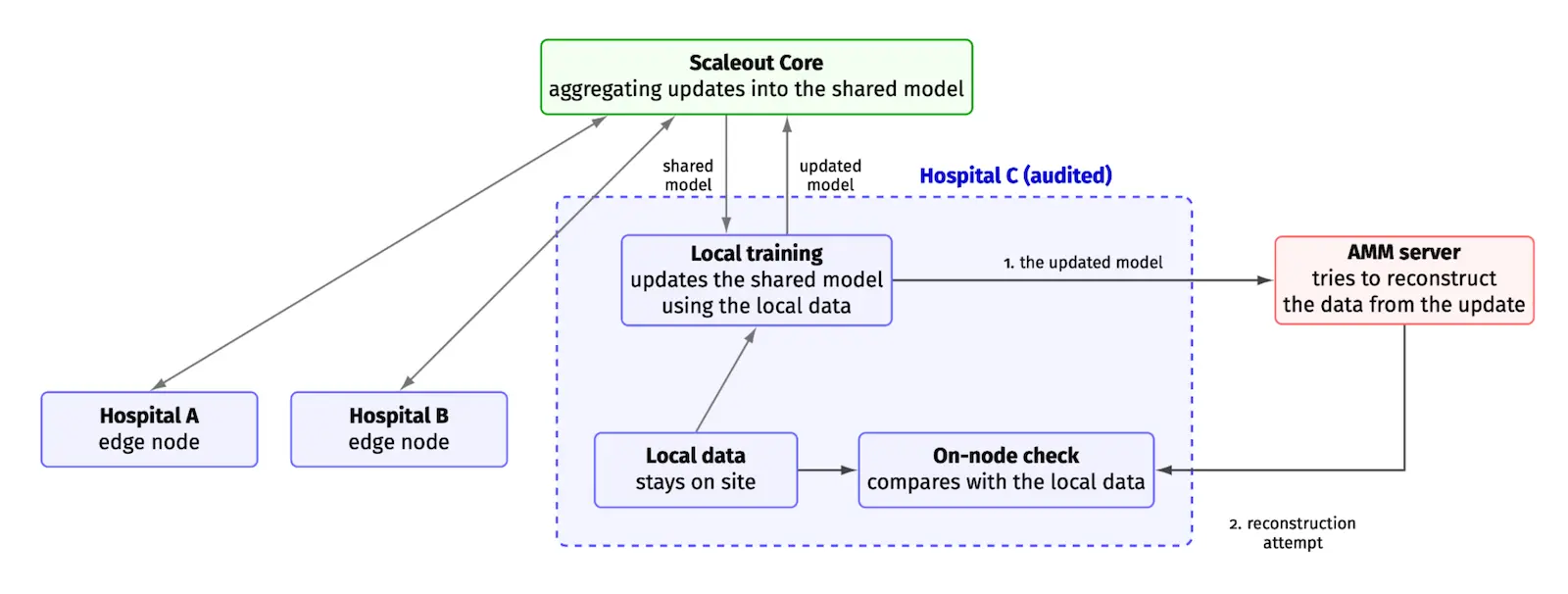
It has to be safe to run on a live system. An audit is worthless if it disrupts the very network it is meant to protect, or quietly drains the resources of the site it is testing. AMM is built so that each edge node stays in control of its own limits, and so that auditing does not disrupt the node's primary work. It can let the audit run quietly in the background, or hold a model update back until the audit has cleared it.
It has to search, not spot-check. A real attacker would not settle for one off-the-shelf attempt; they would tune their approach until it was as effective as possible. So AMM chooses the attacks best suited to what is known about the target and automatically searches across many configurations to find the strongest version of each. What it reports is how the data holds up against a determined, well-tuned attempt, not a convenient one.
And it has to leave a record. A security check that lives on a single laptop is not something anyone can stand behind. AMM keeps a durable, searchable history of what was tested and what was found, so that a network's resilience becomes something you monitor over time instead of a claim made once and quietly forgotten.
Behind these three qualities is a steady stream of engineering work to keep pace with the systems people actually deploy, not the simplified models that happen to be easy to test. Those details matter, but less than the change they add up to: auditing that is continuous, safe and accountable, in place of something occasional and improvised.
Proof, not promise
Federated learning's privacy architecture is sound. The core idea, train locally and share only what is learned, is a meaningful step forward, and the collaboration it unlocks is real.
AMM does not change that architecture; it finishes the job, taking a network that was designed to protect data and making it one that has been tested to prove it.
The organizations that deploy federated AI with the most confidence will be the ones that can answer the hard question not with a diagram, but with evidence. The space between a system believed to be secure and one shown to be secure is exactly what separates a promising idea from a technology ready for the field.