Federated Learning (FL)
In federated learning, multiple clients collaboratively train a machine learning model without sharing their local data. Instead of sending raw data to a centralized server, clients train a model on their local data and only send model parameters to a central server. Federated learning enhances privacy, as raw data never leaves the clients.
If you are new to federated learning and need a comprehensive introduction, I recommend that you register for our workshop at https://www.scaleoutsystems.com/workshop. Also have a look at https://www.scaleoutsystems.com/framework, where you can learn about our federated learning framework FEDn.
While federated learning has many benefits over centralized machine learning, it comes with its own challenges:
- Data Heterogeneity: Each client collects data in a non-iid manner, with data being generated from a distinct probability distribution. Further, the number of data points generated at each client may differ.
- System Heterogeneity: The computational power, storage, as well as communication capabilities may differ across the edge devices due to variability in hardware.
In this blog post, I will introduce multi-task learning, an approach to machine learning that can overcome the challenges of data heterogeneity and system heterogeneity in the federated setting. This makes it interesting to combine multi-task learning with federated learning [1].
Multi-task Learning (MTL)
In machine learning, we usually train a single model on a dataset to perform a specific task. This is the case whether it is in the domain of computer vision, natural language processing, or some other application area. While this approach has turned out to be very successful, this “single-task learning” approach disregards information that may be useful and that could improve our metric of interest.
In multi-task learning, multiple related tasks are learned concurrently by a shared model. This improves model generalization, which leads to a better performance on the original task [2].
Hard parameter sharing
Hard parameter sharing is the most popular method in MTL. Model weights are shared between all tasks -only output layers are task-specific with the goal of jointly minimizing multiple loss functions. Hard parameter sharing can be seen as regularization, since a representation has to be learned that performs well across all tasks, thereby reducing overfitting on one specific task [2]. The figure below illustrates hard parameter sharing.
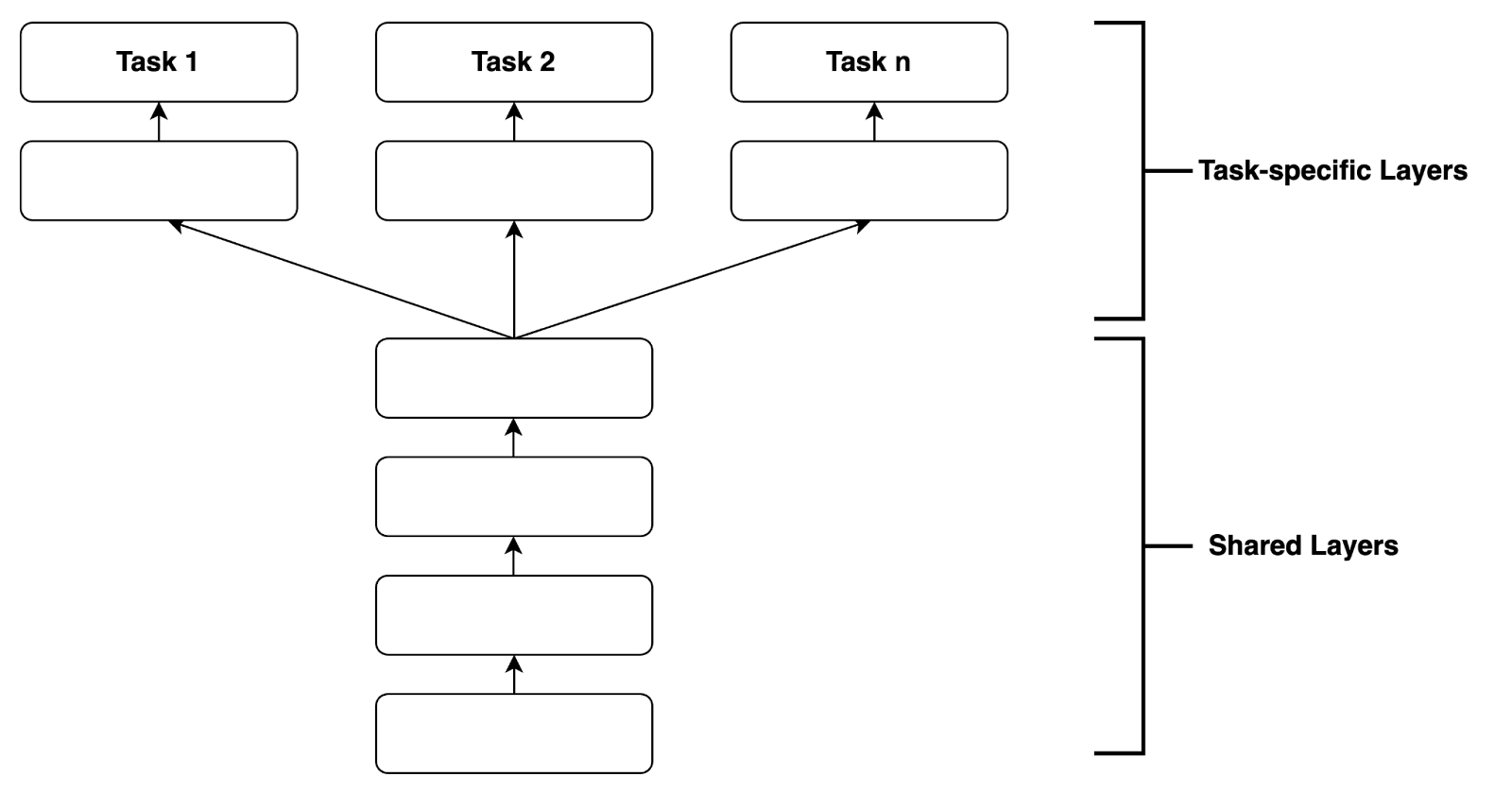
Soft parameter sharing
On the other hand, soft parameter sharing trains separate models for each specific task. Rather than sharing the exact same parameters between the task-specific models, soft parameter sharing encourages the parameters between the models to be similar by penalizing divergence between parameters [2]. Soft parameter sharing is illustrated in the figure below.
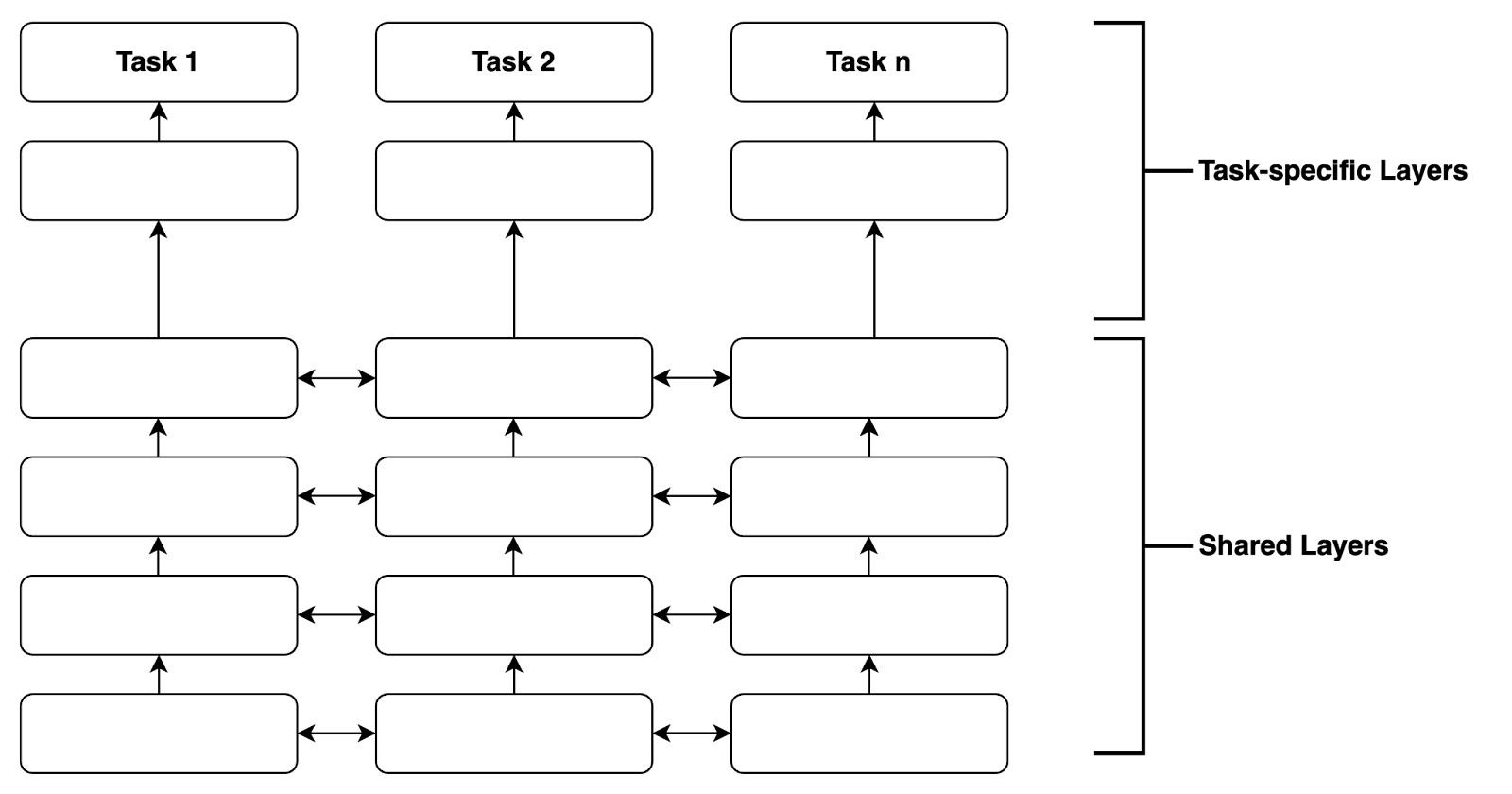
Federated Multi-Task Learning (FMTL)
Let me motivate federated MTL with an example. Imagine two hospitals - both having their own dataset that they are not allowed to share due to privacy regulations. Both datasets consist of chest X-rays, but hospital 1 wants to detect different types of lung diseases, whereas hospital 2 wants to detect heart diseases. While the tasks are different, they are related to each other and the hospitals can benefit from knowledge sharing as it can improve the overall performance of the models. Federated multi-task learning is highly suitable for this use-case.
The figure below visualizes federated multi-task learning for a more general scenario with hard parameter sharing. As in standard federated learning, a server performs model aggregation and sends the global model to the different clients. Now, the clients perform their task-specific training locally and only send the model parameters that are shared between the clients to the server, which aggregates the model parameters to a new global model. The task-specific parameters are not sent to the server.
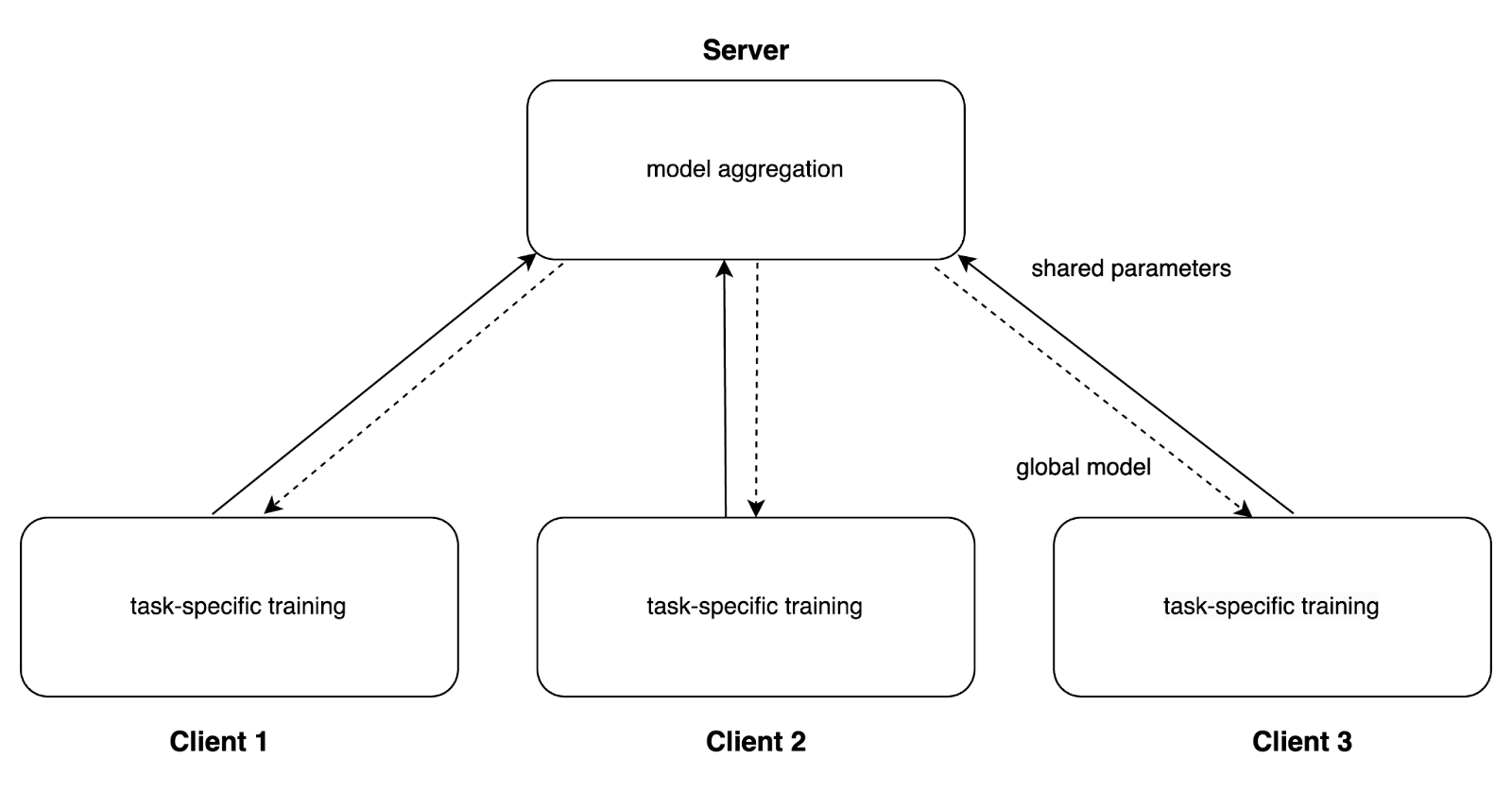
Another way to motivate MTL in the federated learning setting is that it naturally deals with data and system heterogeneity. In classical federated learning, a single global model is learned to fit the data across all clients. As each client may generate data from a distinct data distribution, model performance can vary across clients. With MTL however, it is possible to learn separate models for each client, thereby taking the heterogeneity into account. MTL deals with system heterogeneity, as clients can train models that fit their computational capabilities. As only shared parameters are aggregated on the server side, each client can contribute to the global model despite different computational capabilities. Additionally, MTL deals with data heterogeneity, as clients can train task-specific models on their own data distribution. By adding a regularization term, it is possible to enforce the local models to be similar to the global model, which encourages the local models to take global information into account. Li et al. [3] propose an L 2 regularizer which forces the local models w k to be similar to the global model w*:
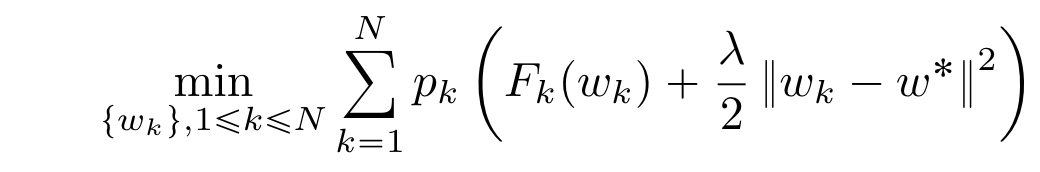
where λ is a hyperparameter and F k (w k) is local loss for client k.
Note that the parameter λ controls the level of personalization of the local models: If λ is large, local models are forced to be similar to the global model, meaning that local models are similar to each other. If λ is small, the opposite is the case and local models will be more personalized.
Hard and soft parameter sharing in MTL is closely related to the described setting. Federated MTL with hard parameter sharing enforces the shared layers between the clients to be identical. Federated MTL with soft parameter sharing however allows for more personalization, as parameters between the local models are allowed to differ.
Summary
This blog post introduced multi-task learning as a method that improves model generalization by training a shared model across multiple related tasks. Using multi-task learning in a federated setting is a natural way to deal with data and system heterogeneity, and allows for personalization of local models.
References
[1] Smith, Virginia, Chiang, Chao-Kai, Sanjabi, Maziar, and Talwalkar, Ameet. "Federated Multi-Task Learning". In: CoRR abs/1705.10467 (2017). http://arxiv.org/abs/1705.10467.
[2] Ruder, Sebastian. "An Overview of Multi-Task Learning in Deep Neural Networks". In: CoRR abs/1706.05098 (2017). http://arxiv.org/abs/1706.05098.
[3] Li, Tian, Hu, Shengyuan, Beirami, Ahmad, and Smith, Virginia. "Federated Multi-Task Learning for Competing Constraints". In: Neural Information Processing Systems (NeurIPS 2020). (2020).