The impact of the backdoor attack
Scaleout
May 7, 2024
This is the second part of our input privacy series, focusing on the implications of established adversarial attacks on federated learning. It's worth noting that while extensive literature exists regarding adversarial attacks on centralized models, reassessing the attack scenario within federated environments is paramount. As explored in our previous post, the unique dynamics of federated training and the aggregator's role significantly alter the attack's repercussions.
This time we explore backdoor attacks and their effects on the global model. We assess the entire backdoor mechanism, closely examining its structural intricacies and impact. These new insights highlight the severity and implications of backdoor attacks on federated model training.
To get upp to speed be sure to check out our previous blog posts:
The impact of label-flipping attack
And in this text we discuss the broader context of input and output privacy:
Output privacy and federated machine learning
The Backdoor Attack: A Stealthy Threat to Federated Learning
Among adversarial attacks, the backdoor attack stands out as a particularly insidious threat to federated model training. In a backdoor attack, a malicious actor introduces a hidden trigger or pattern into the training data, which the model learns to recognize. This trigger has no impact on normal data but can be exploited to manipulate the model's predictions when the trigger is present.
In the context of federated learning, a backdoor attack can have severe consequences. Since models are trained across distributed devices or servers, a compromised model with a backdoor can spread the vulnerability across the federated network. This not only compromises the model's accuracy and reliability but also raises concerns about the integrity of data across participating entities.
Experiment setup
For the experiments, we have used the MNIST handwritten dataset comprising a total of 70,000 images, divided by default into 60,000 images for training and 10,000 images for testing. These tests are then subdivided into 10 partitions, each assigned to an individual client. The data partitions are balanced using IID settings. The model was trained using a commonly known neural network classification PyTorch model architecture.
- https://paperswithcode.com/dataset/mnist
- https://www.kaggle.com/code/faduregis/mnist-digit-classification-in-pytorch
The attack described is a targeted backdoor attack, in which images of the digit "6" are marked with a backdoor indicated by the symbol "+". These altered images belong only to the malicious clients.

For the experiments, we selected the following three settings:
- Baseline: This includes all honest clients and serves as the foundation for training the federated model and assessing its accuracy.
- 10% Malicious Clients: In this setting, 10% of the clients in the federation are malicious, and all the images of one specific digit “6” are marked with the backdoor “+”.
- 20% Malicious Clients: In this setting, 20% of the clients in the federation are malicious, and like in the previous setting, all images of one specific digit “6” are marked with the backdoor “+”.
We worked with a total of ten clients, of which 10% and 20% were malicious clients within the federation. We opted not to include a higher proportion of malicious clients, as elaborated in detail in part 1 of the blog post:
The training dataset for malicious clients contains all images of the digit "6" with the backdoor, whereas normal clients have all clean images in the training dataset.
Results and discussion
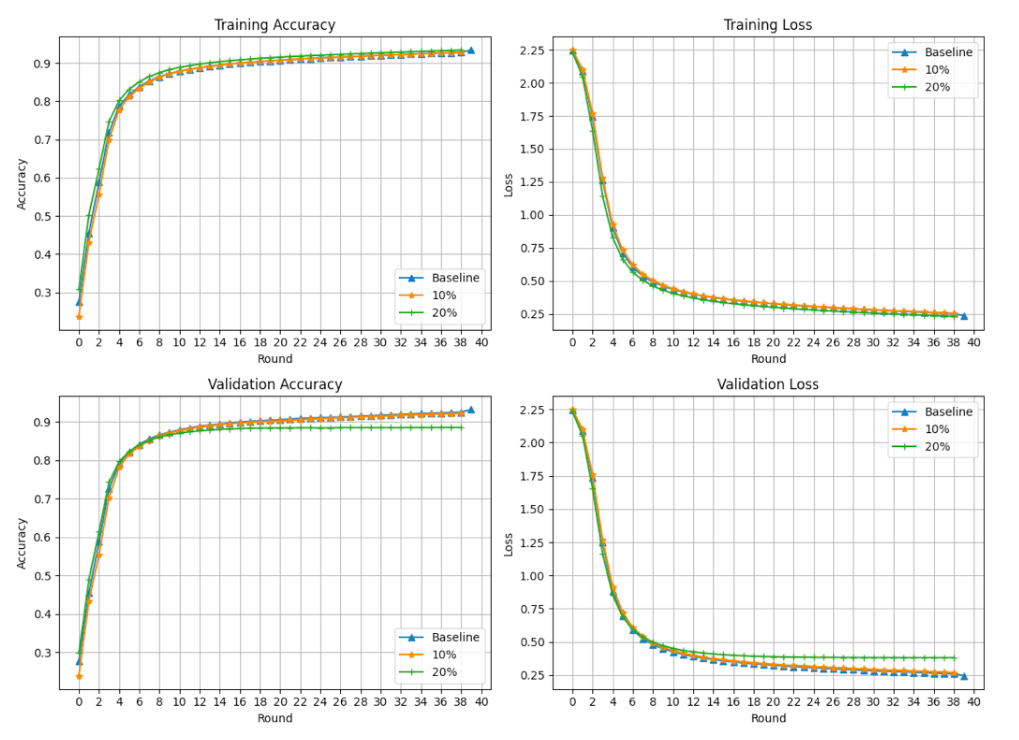
The following plots display training accuracy, training loss, validation accuracy, and validation loss from a ten-client-based federated training process. The plot includes accuracies from a completely honest federation (blue curve), used as our baseline. Additionally, it shows a federation of ten clients with 10% malicious clients (orange curve) and another with 20% malicious clients (green curve). Each curve represents a separate experiment, averaging three executions, where data is shuffled in each run while using the same digit "6" images for the backdoor.
The figures showcase borderline differences between the three curves, except for a slight change in validation accuracy between rounds 35 to 40. However, this difference isn't significant enough to conclusively detect an attack on the federation. Therefore, in conventional training and validation processes within federated settings, backdoor attacks are not easily detectable.
We also examined the attack's impact on the test dataset. To do this, we created five different scenarios and evaluated the accuracy of global models trained across the above-mentioned three federations: all honest clients, 10% malicious clients, and 20% malicious clients. Here are the specifics of the five test datasets.
- Test dataset with all clean images.
- Test dataset with all images having the exact defined structure of the backdoor "+". The same structure of the backdoor was used during training with malicious clients.
For the next three test datasets, we explored how the model is affected when the exact structure of the backdoor is not present, rather than variations introduced in the structure of the backdoor. The backdoor used in this study consists of a combination of horizontal and vertical lines “+”.
By "variation in the structure," we mean making changes to the backdoor to observe their impacts. It's important to note that no changes were made to the training dataset. The originally defined “+” structure was applied to a single digit "6" for malicious clients.
Here are the test datasets based on these variations:
- 3a. Test dataset with extended horizontal and vertical lines in each test image.
- 3b. Test dataset with a single extended horizontal line in each test image.
- 3c. Test dataset with a single extended vertical line in each test image.
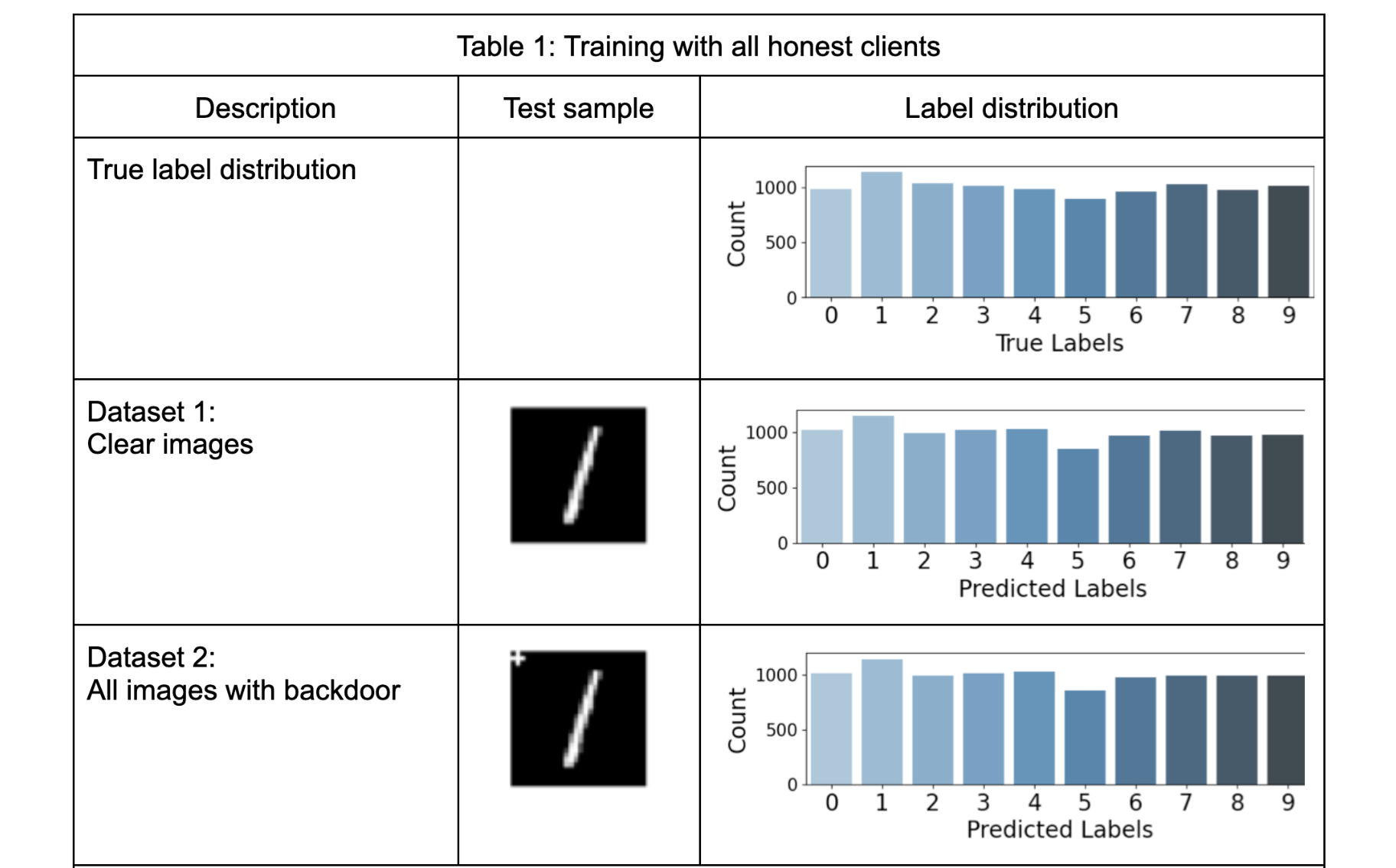
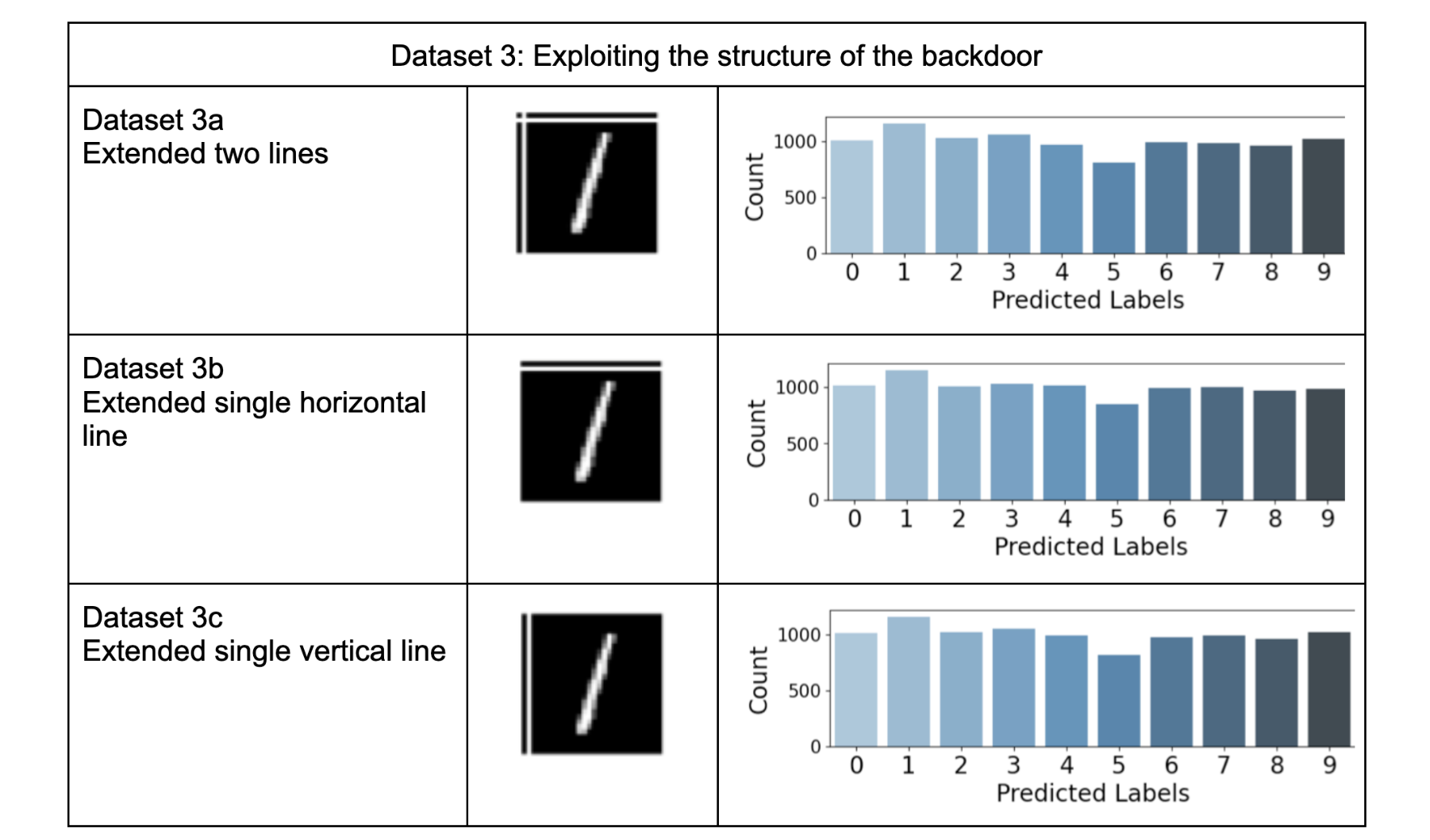
Table-1 presents the results of five test datasets where training and validation were conducted solely with honest clients. This means the model is completely unaware of the backdoor. We use a clean test dataset (dataset1), a test dataset with a backdoor embedded in each test image (dataset2), and variations of the backdoor (dataset 3a, 3b, and 3c). These experiments consider the backdoor in test images as noise, highlighting the robustness of the global models in non-compromised setups. The bar plots in the table align with the expectations. Since the backdoor was not part of the training process, it had an insignificant impact on model accuracy. However, in datasets 3a, 3b, and 3c, a slight difference is noticeable when closely examining counts on labels 8 and 9.
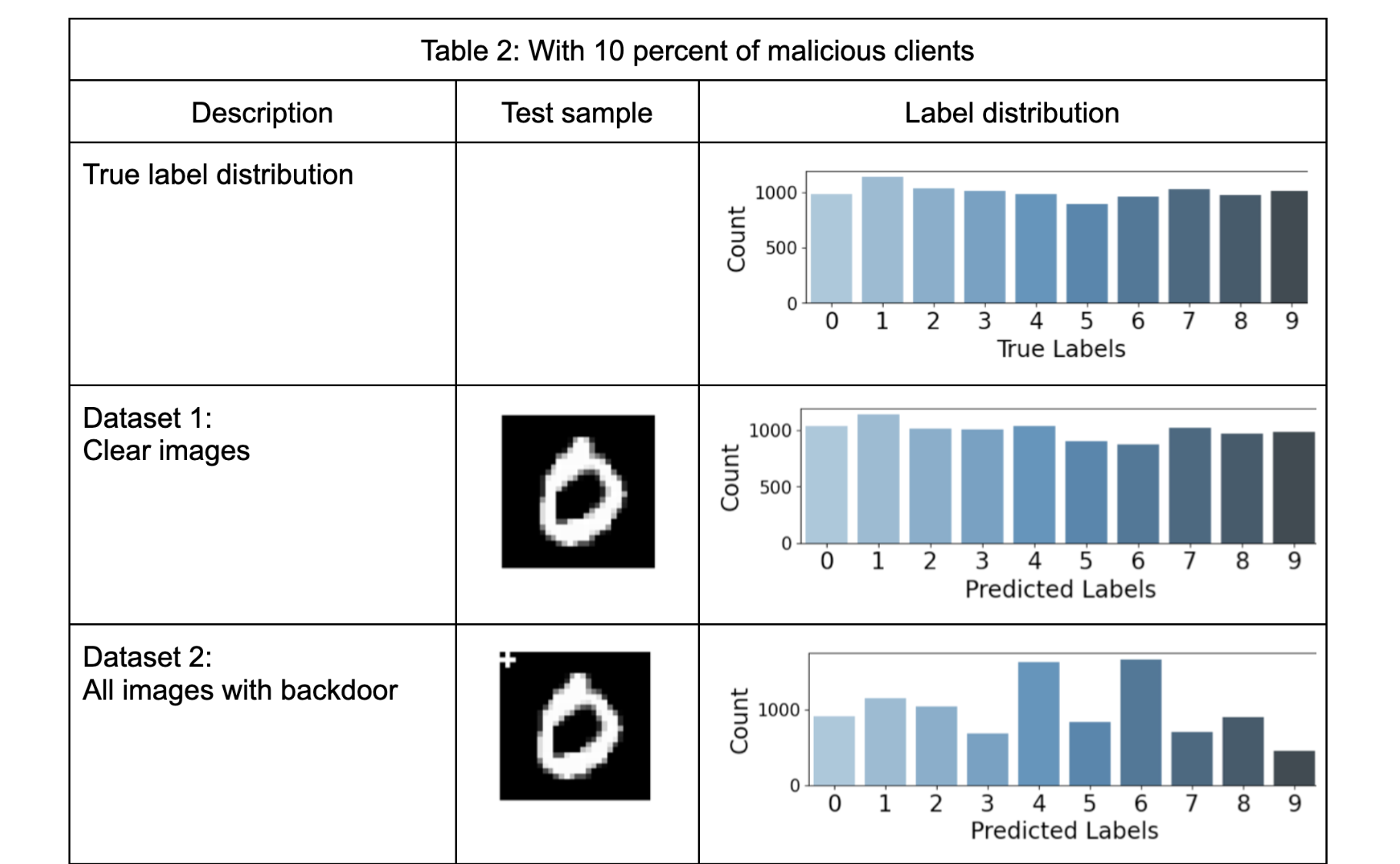
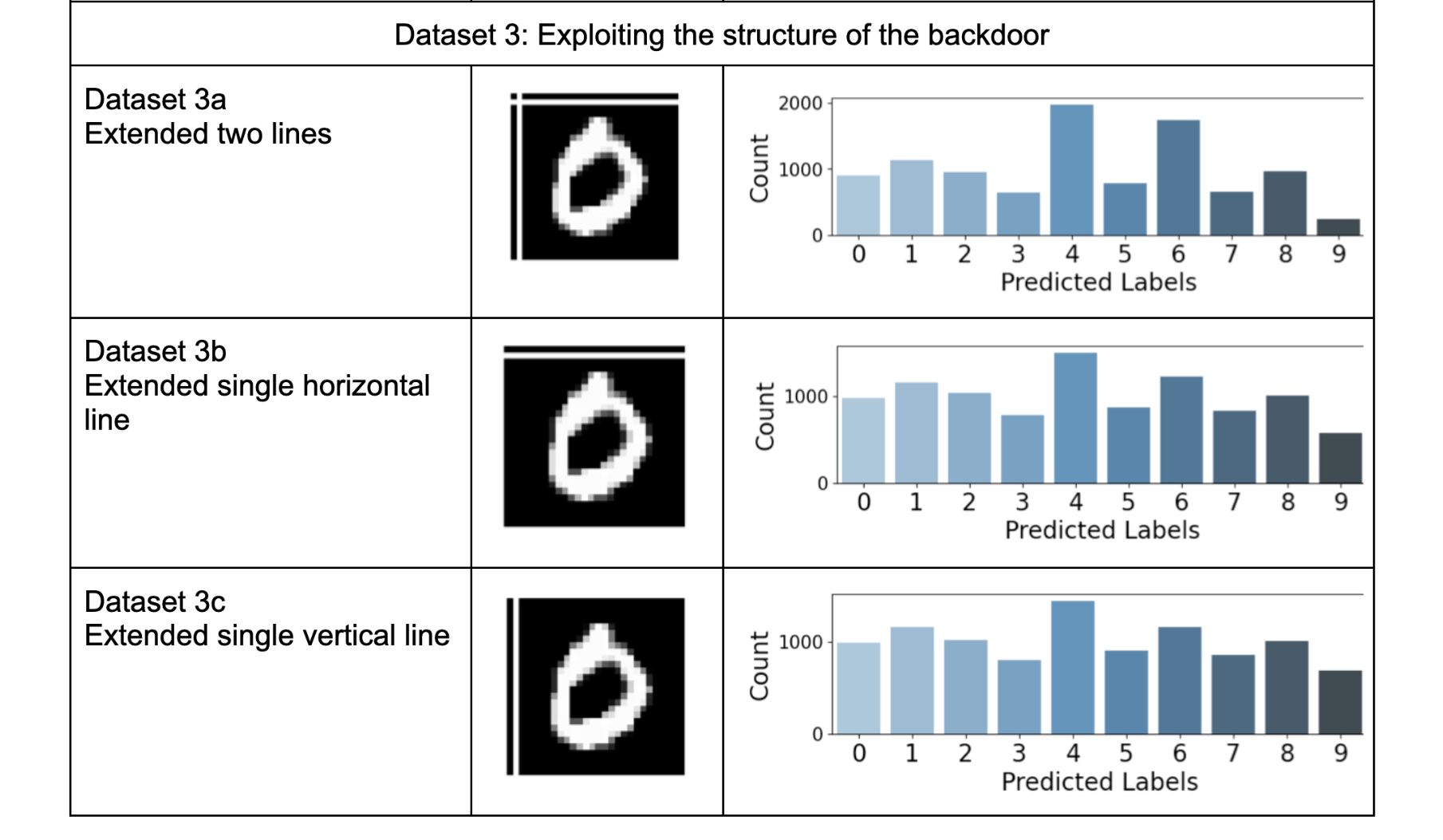
Table-2 presents the results of five selected test datasets when there are 10% malicious training clients in the federation. It's important to note that the training dataset only contains images of one class with the backdoor, specifically digit "6".
Test dataset 1 in Table 2, demonstrates the expected behavior, the compromised global model behaves normally without the presence of the backdoor. However, when the backdoor is introduced, Dataset 2 in Table-2, in the test dataset across all labels, there is a drastic negative impact on the model's performance. The counts for label “6” increased significantly. The backdoor successfully pulls the predictions to label “6”. Another important insight is the increase in the number of counts of label “4”. This is mainly because of the similarity in the images of labels “6” and “4” when written by hand.
This negative effect persists even when the exact structure of the backdoor is not part of the test images. Test datasets 3a, 3b, and 3c in Table 2, also underscore that even a partial structure of the backdoor has a strong negative effect. This is particularly concerning as it allows for a significant impact on the model without fully revealing the original structure of the backdoor.
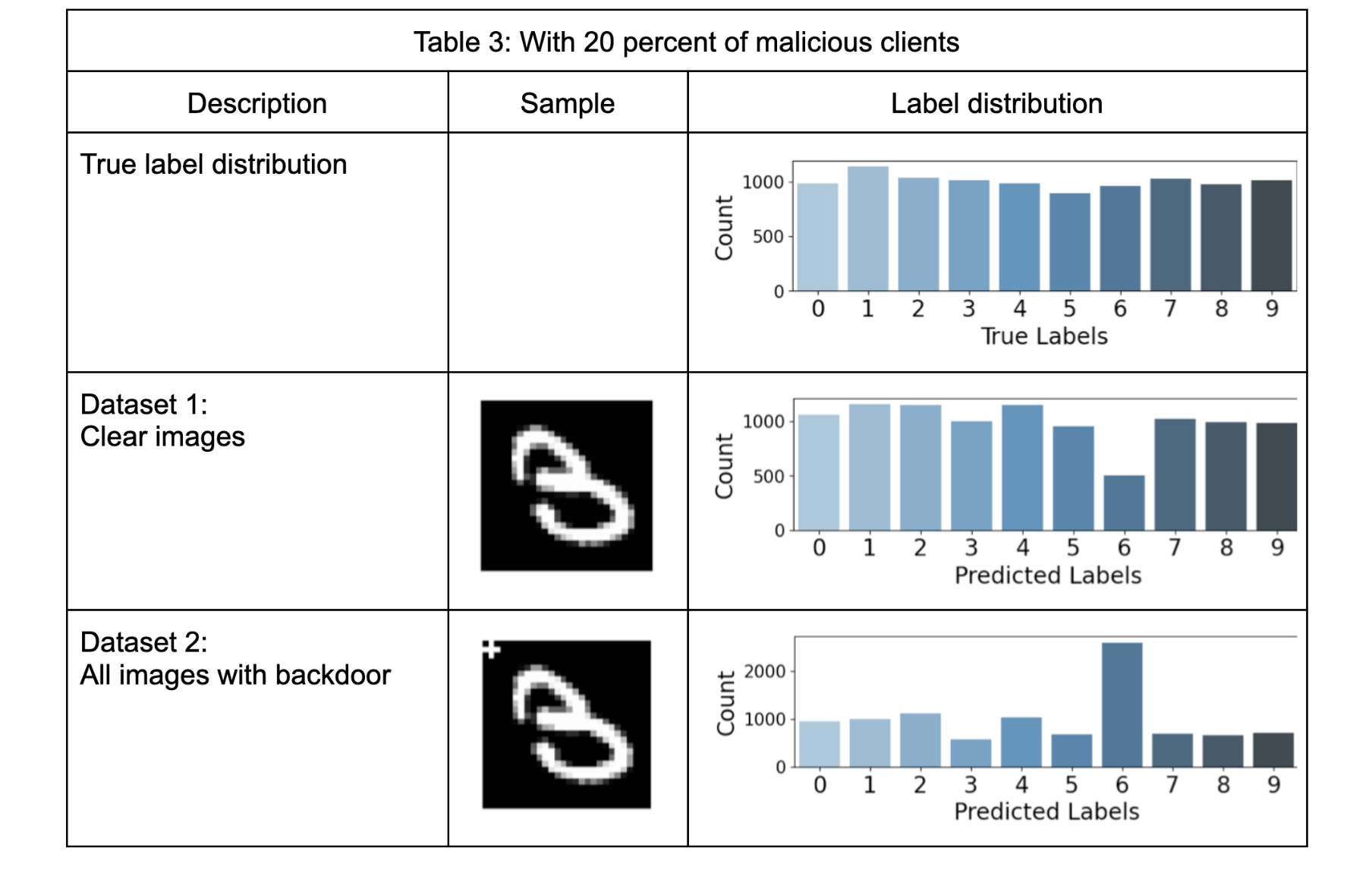
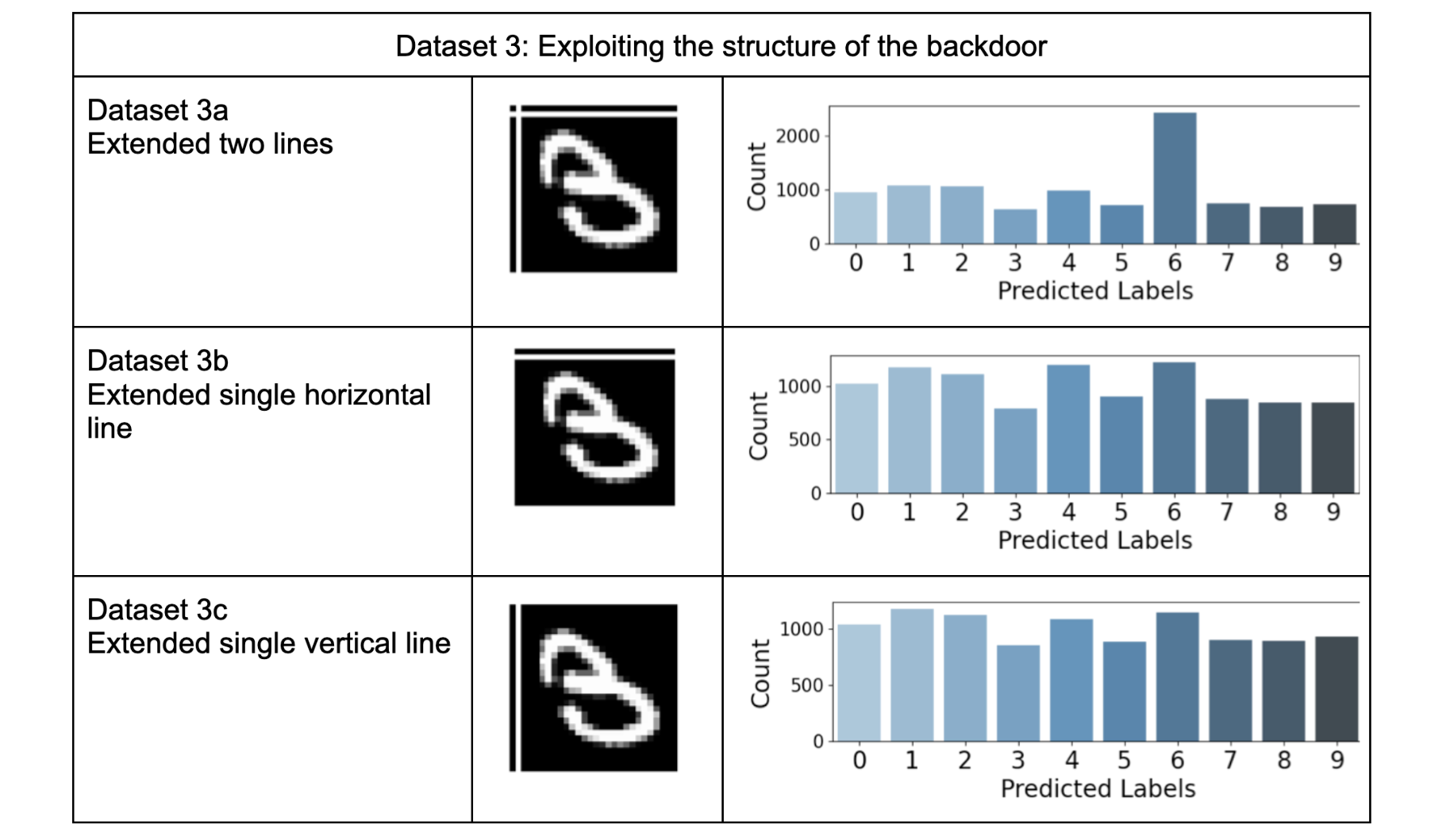
Table-3 presents results similar to Table-2 but with an aggravated negative impact on the global model. In dataset-2 Table 3, we observe a strong effect of the backdoor, causing almost all test samples to be classified as the targeted label (digit 6). This effect persists even when structural variations are introduced in the backdoor. For instance, test dataset 3a in Table 3, shows a similar impact to dataset 2 in Table 2. Additionally, in test datasets 3b and 3c, the incorrect predictions on other labels contribute to an increase in the counts of the targeted label (digit 6).
Remedies of Backdoor attacks
The experiments presented here underscore the impact of backdoor attacks in traditional federated machine learning setups, even with a relatively small number of malicious clients (10% or 20%). State-of-the-art literature offers various strategies for identifying and mitigating these attacks in centralized training settings. For instance, Article [1] emphasizes that backdoors often leave discernible traces in the latent or feature space, which can be leveraged to counter backdoor attacks. Meanwhile, Article [2] advocates for neural attention distillation as a means to eliminate backdoors. These, along with several other approaches [3, 4], stand as potential methods for mitigating backdoor attacks in federated settings.
Scaleout Systems, with its core focus on privacy-preserving machine learning, possesses unique expertise in federated machine learning. Our team of experts has substantial experience in researching and developing federated machine learning solutions. We support practitioners in comprehending various challenges, adopting best practices, and exploring possible solutions tailored to their federated learning needs. This series of blog posts aims to delve into significant technical challenges, and in future posts, we will delve into solutions to these highlighted challenges.
Summary
The results present the significant impact of backdoor attacks, which pose a considerable challenge to detect in traditional federated model training setups. Furthermore, not only does the exact structure of the backdoor have a substantial impact, but variations in its structure also harm model performance. This is particularly concerning as it conceals the actual backdoor while still affecting the model.
It's important to note that, for the sake of simplicity and general understanding, we used a basic backdoor in our experiments. Recent developments have led to techniques for creating backdoor images that are visually indistinguishable from clean images, enhancing the stealthiness of backdoor attacks from the input space. A more sophisticated backdoor could potentially have an even greater impact than what is presented here.
While backdoor attacks are stealthy, the literature offers possible solutions in centralized settings. Scaleout is committed to addressing cybersecurity challenges in federated learning, and in our upcoming posts, we will discuss other attacks and also the best practices to mitigate the effects of such attacks.
Acknowledgments
The results presented in this post are derived from the project report "Evaluating Model Poisoning Attacks in Federated Machine Learning" prepared for the Computational Science project course at Uppsala University, Sweden.
References:
[1]. Doan, Khoa, Yingjie Lao, and Ping Li. "Backdoor attack with imperceptible input and latent modification." Advances in Neural Information Processing Systems 34 (2021): 18944-18957.
[2]. Li, Yige, et al. "Neural attention distillation: Erasing backdoor triggers from deep neural networks." arXiv preprint arXiv:2101.05930 (2021).
[3]. Wang, Bolun, et al. "Neural cleanse: Identifying and mitigating backdoor attacks in neural networks." 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019.
[4]. Guo, Wei, Benedetta Tondi, and Mauro Barni. "An overview of backdoor attacks against deep neural networks and possible defences." IEEE Open Journal of Signal Processing 3 (2022): 261-287.